Upfront disclaimer: This page is strictly about the vintage P1 ROM from the 90s! I did NOT do any datamining on the remakes and this information MAY NOT be valid for them!
I spent around 1-2 months in 2023 analyzing the P1 ROM (this used to be available on the Internet Archive, not sure if it still is). I specifically wanted to figure out how the P1's growth chart works. Ultimately, I want to perform the same analysis on other models, for some future time that their ROMs become available. To that end, I shipped some Mothras, some Angelgotchis, and some Tamaotchs to a guy who can decap and image the ROM -- this is still a work in progress.
Anyway, I want to write down what I did so that I can help jog my memory later... this is very much a quick-and-dirty page and I assume a lot of prior knowledge. Maybe someday I'll flesh it out, but for now I just want to capture the main points of what I did.
I have never reverse engineered anything before -- not a professional programmer or electrical engineer, I'm just some donkus with hobbyist interest in those fields. But most of the hard work has already been done, since the P1 ROM has already been dumped and we know what kind of CPU the P1 uses (Epson E0C6S46). So I started by getting the datasheets for the P1 CPU and the programming guide -- I don't think there any issues if I share those files, so here they are:
With the datasheets in hand, I opened the P1 ROM in Ghidra. This is a reverse engineering tool that you can use to open a binary file and look at the code contained within; it has extensible parsing capabilities that allow it to figure out and display the code in the file.
Now, Ghidra does not natively know how to parse the binary format used by the P1 ROM. But fortunately, there is an existing Github project with parsers for the E0C6S46 format. I fixed up the parsers and submitted a pull request that was accepted, so the project should be usable for anybody at this point. Install it in Ghidra (should just be able to create a folder 'E0C6S46' in Ghidra build location/Ghidra/Processors and copy the contents of the repo into there) and you are ready to go.
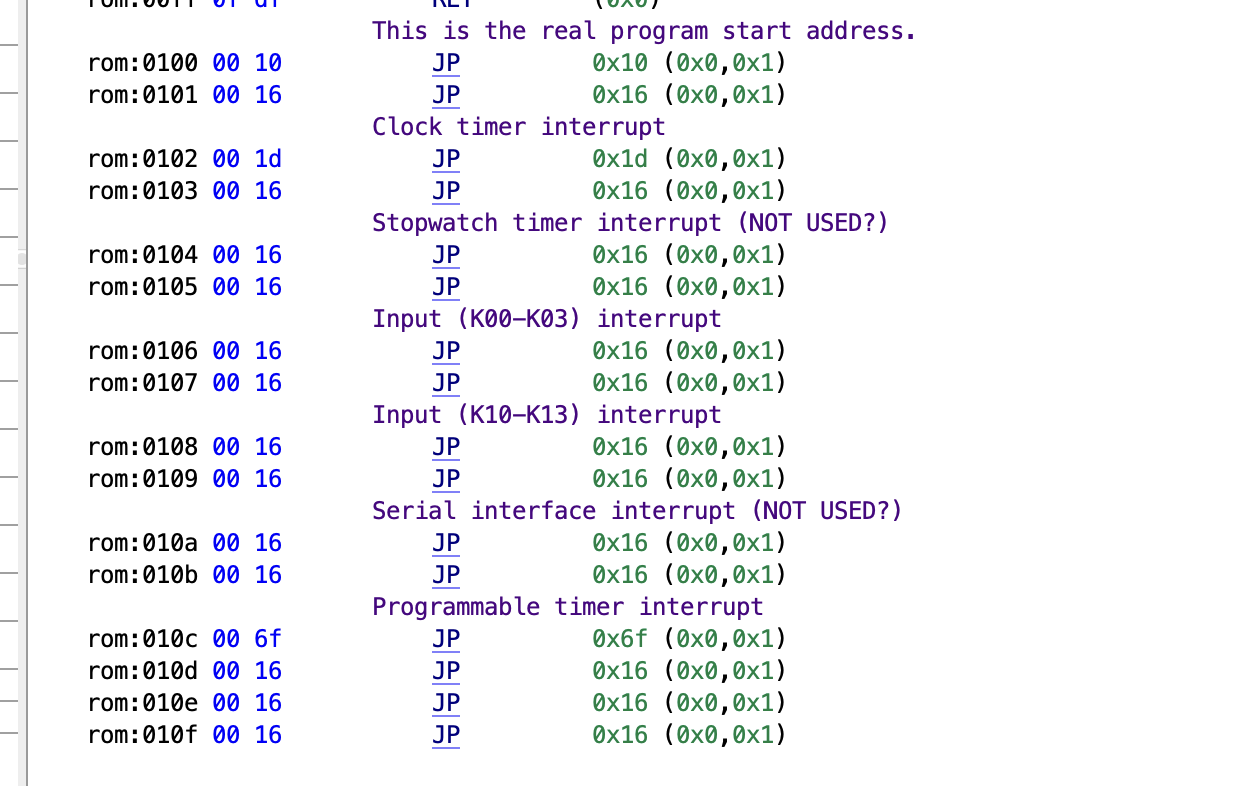
My first approach was just to read the P1 code, starting from where the program begins. Per the technical manual (4.1.5), I know that the Tama program starts at address 0x00, page 0x1, bank 0x0. In Ghidra, this appears as address 0x0100 as shown below (note that the interrupt vector is also stored here -- I have it annotated in the screenshot)
For reference, here is the layout of the ROM as described by the technical manual:
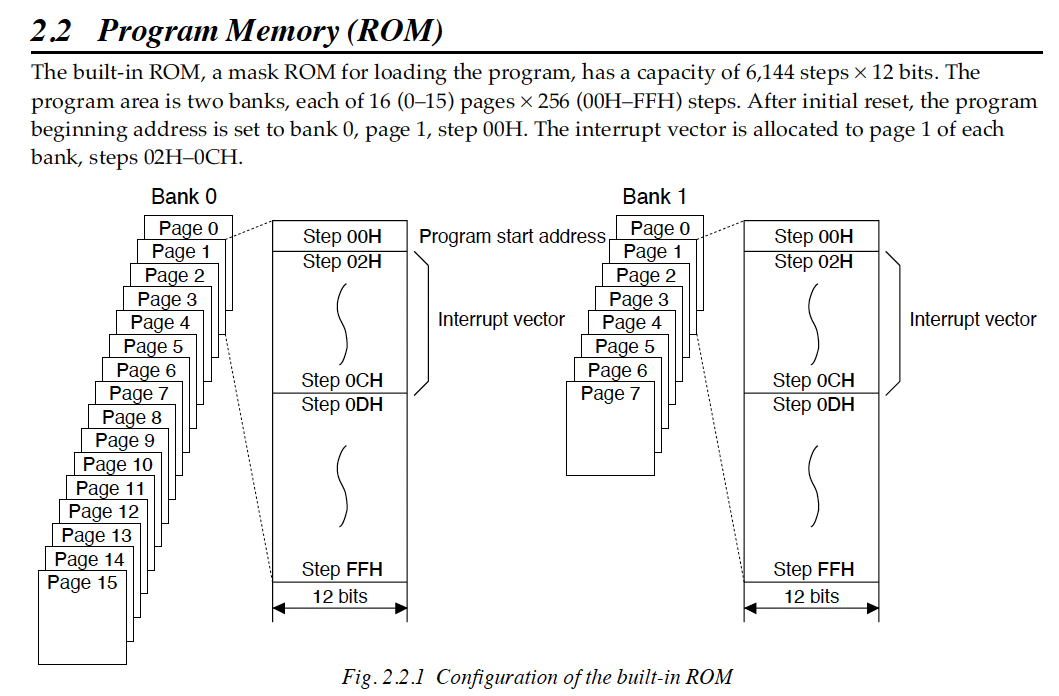
The ROM addresses as shown in Ghidra reflect this -- first digit is bank, 2nd digit is page, and the last 2 digits are the address within the page.
So at first, I simply followed the code as it proceeded from startup, initializing registers and I/O, etc. Eventually I realized this is extremely inefficient and I probably would never get anywhere doing this. At this point I started looking for a way to run the P1 code and follow how it worked -- ultimately I landed on MAME which has support for the P1 ROM and good debugging capabilities. You can inspect memory, pause execution, set breakpoints, etc. (go here for the full documentation) There are tools out there specifically for running the P1 ROM, but they didn't have the debugging capabilites I was interested in.
To open not in full-screen mode and to enable debug, I invoked mame on the command line as:
mame -window -debug
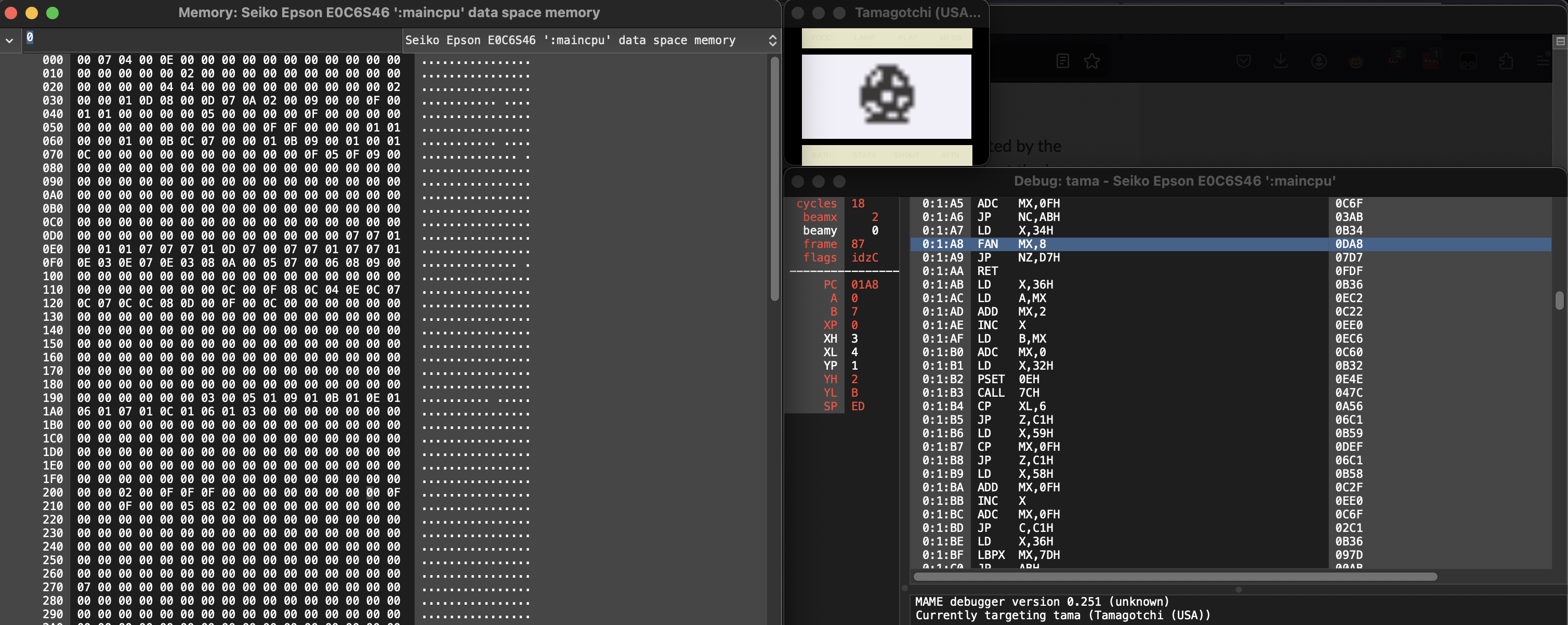
So basically what I did from this point was an extremely grueling, time-consuming process of watching what the code was doing, and how the contents of RAM were changing. I was able to annotate more and more of the ROM in Ghidra, leaving less and less unknown code. Eventually, I was able to figure out what I wanted -- how the P1 growth chart works.
I really wish I'd done this writeup earlier so I remembered better what I did. But anyway here were some general notes that I found useful:
So enough technical nerd stuff for a second. Did I learn anything cool about Tamas from all this? YES
I'm going to attach a couple of the outputs from this process to this page.
I wasn't sure if the Ghidra project with my annotations is anonymized so I refrained from uploading it... for now
So with this project I pretty much assured myself that I can, given the ROM, figure out how the code works. But what I'm expecting from the decapping project is just an image of the ROM, so there are 2 extra steps before I can start looking at the ROM:
The project to decap and image the Mothra/Angelgotch/Tamaotch is not complete yet, but a rough scan WAS made of the Mothra, and I surmised from it that the CPU model used by the Mothra is most likely a E0C6S48. This is basically the same thing as the E0C6S46 which gives me hope that, once a ROM is available, very little work will be required to get it working in MAME, so analysis will have a quick start for it. For future reference, the datasheet is here
Although I eventually did find an existing parser on GitHub for the P1 CPU, I did have to do a lot of rework on it and I did have to scrounge around for resources on how to do that. (plus I originally tried to start from scratch).
The system used to write new parsers for Ghidra is called Sleigh. I found it kind of a nightmare to work with.
Unfortunately I no longer remember how I invoked sleigh to compile my in-progress parsers. It comes with the Ghidra builds (look in the 'support' folder). But basically I would just make a change to the parser, run Sleigh, install the updated files, then restart Ghidra and try to parse the ROM again. Once it output the results I wanted, I was happy.
In general, I think that due to the weird way the P1 CPU architecture works, Ghidra is able to do less static analysis on the ROM than it can for other architectures. So it basically never knows what the input to a function is unless you figure it out from using MAME or manual inspection, doesn't know the results of calculations, and can't build those cool looking code trees like you see in RE writeups that are better than this one. (and like I already mentioned, Ghidra tended to mess up the function definitons, so you have to manually remove a lot of the autogenerated labels and functions -- this was a satisfying activity though since you are reducing the overall number of functions you need to worry about for free...)
The most important source for figuring out how to use Sleigh is, unfortunately, the Sleigh language specification. These come with Ghidra -- in my build, I found them in docs/languages/html. But they're kind of hard to decipher unless you have other Sleigh files to reference against.
Random stuff I looked at at various points, just figuring out where to look was kind of difficult, so I'd like to leave the breadcrumbs for all to see...